机器学习V - 支持向量机(Support Vector Machines)
7. 支持向量机(Support Vector Machines)
先从SVM模型的分类问题入手,上述已经学习的逻辑回归的代价函数如下
为了便利,我们使用$cost()$来代替其中的一部分
与逻辑回归不同的是,SVM的$cost()$函数需要满足以下条件
逻辑回归的分类界限为0,而SVM为1和-1,更加严格,这样也就会用一个区域两组样本分开,不仅仅是一条线,而最大化这个区域,也就是最好的分类器。
并且 $C = \frac{1}{\lambda}$,以及忽略常数项,SVM的代价函数为
假设函数为
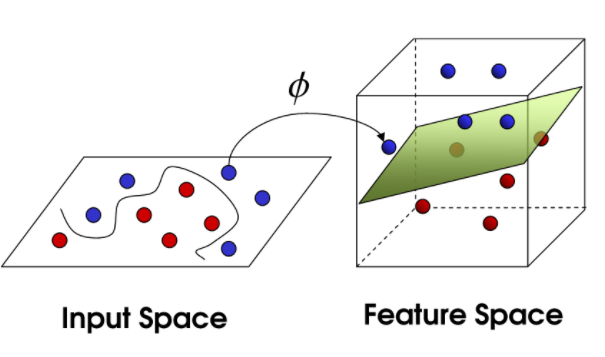
7.1 核函数
核函数是将训练样本进行增维,转化为线性可分
根据$(x^{(1)}, y^{(1)}), (x^{(2)}, y^{(2)}),…, (x^{(m)}, y^{(m)})$
选择$l^{(1)} = x^{(1)}, l^{(2)} = x^{(2)},…, l^{(m)} = x^{(m)}$
所以$f_m^{(i)} = similarity(x^{(i)}, l^{(m)})$
其中高斯核函数为
则有向量
使用了核函数的SVM模型的假设为:
根据$x$,计算出特征$f \in \mathbb{R}^{m+1}$,当$\theta^Tf\geq0$时预测$y=1$
代价函数为:
7.1.1 SVM参数
$C\ \ or \ \ 1/\lambda$
$C$大会导致低误差,高方差,反之亦然
$\sigma$
$\sigma$大会导致特征比较平滑,高误差,低方差

7.2 应用
$n$ = 特征数量,$m$ = 样本量
$n$大(相对于样本量来说),使用逻辑回归,或者不使用核函数的SVM
因为样本量多时,使用核函数很慢,需要遍历所有特征
如果$n$小,可以使用核函数的SVM
如果$n$小,$m$大,建立其他特征,之后使用逻辑回归,或者不使用核函数的SVM